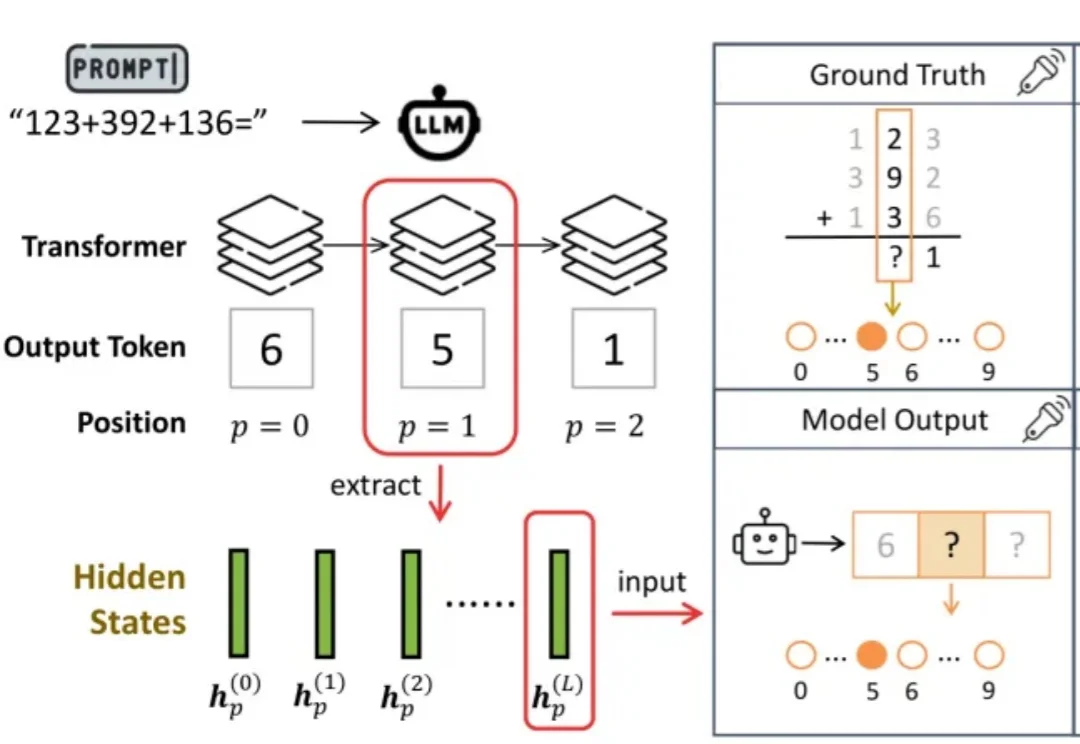
ICML 2026 | 大模型为什么算不对加法?南大团队提出等本位和轨迹,揭示LLM算术错误的几何机制
ICML 2026 | 大模型为什么算不对加法?南大团队提出等本位和轨迹,揭示LLM算术错误的几何机制尽管大语言模型(Large Language Models, LLMs)在复杂数学推理、代码生成和知识问答上表现突出,但它们仍常在多位数加法这类基础算术任务上犯错。
来自主题: AI技术研报
7210 点击 2026-06-17 14:05
 搜索
搜索
尽管大语言模型(Large Language Models, LLMs)在复杂数学推理、代码生成和知识问答上表现突出,但它们仍常在多位数加法这类基础算术任务上犯错。
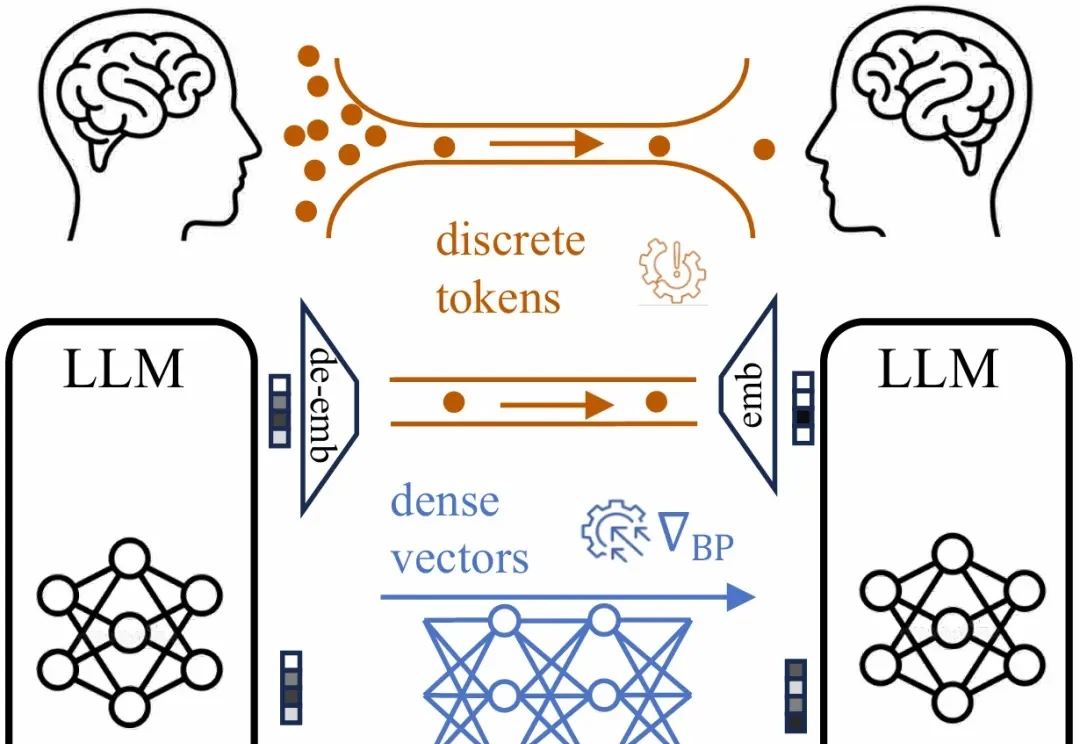
大语言模型正在成为人工智能系统的核心组件。从文本生成、数学推理到代码编写,单个大模型已经展现出强大的能力。

7×24,AI也吃不消。

2026 年初,浙江大学发表了一篇系统性的 SoK 论文《Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward》,给Skill下了一个正式定义。
本文主要介绍来自该团队的最新论文:Scalable Object Relation Encoding for Better 3D Spatial Reasoning in Large Language Models。
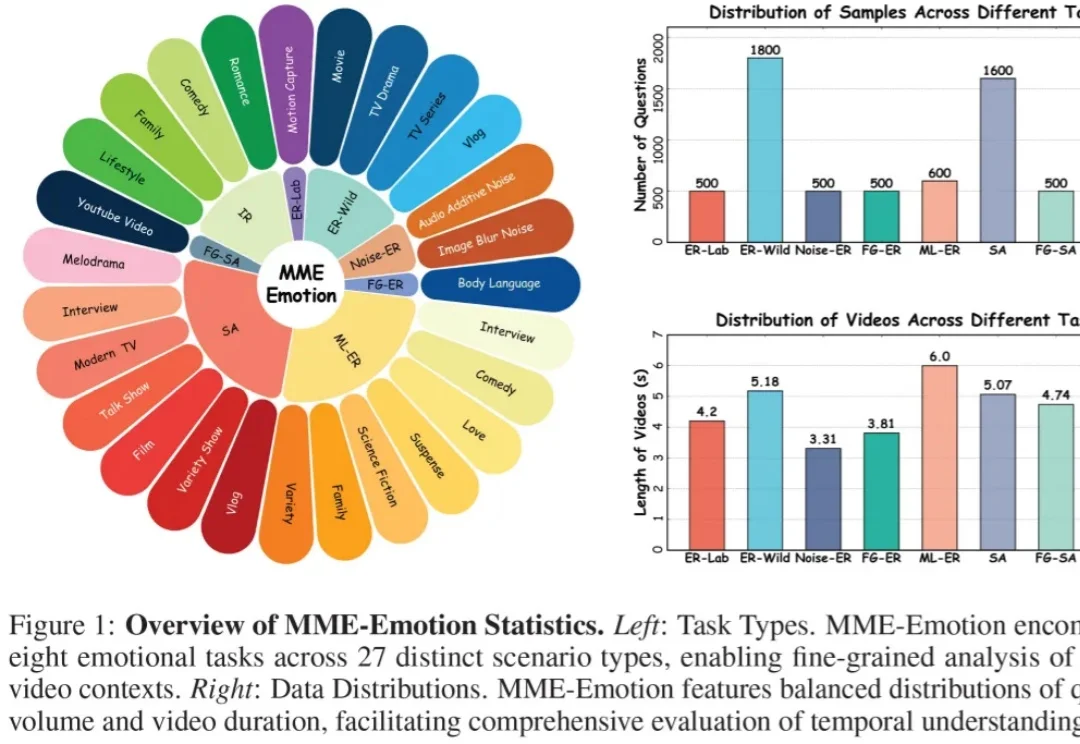
近年来,多模态大模型(Multimodal Large Language Models, MLLMs)正在迅速改变人工智能的能力边界。从图像理解到视频分析,从语音对话到复杂推理,大模型正在逐步具备类似人类的综合感知能力。但一个关键问题仍然没有得到充分回答:这些模型真的能够理解人类情绪吗?

近期发表于 TMLR 的论文《Large Language Model Reasoning Failures》对这一问题进行了系统性梳理。该研究并未围绕 “模型是否真正理解” 展开哲学层面的争论,而是采取更加务实的路径 —— 通过整理现有文献中的失败现象,构建统一框架,系统分析大语言模型的推理短板。
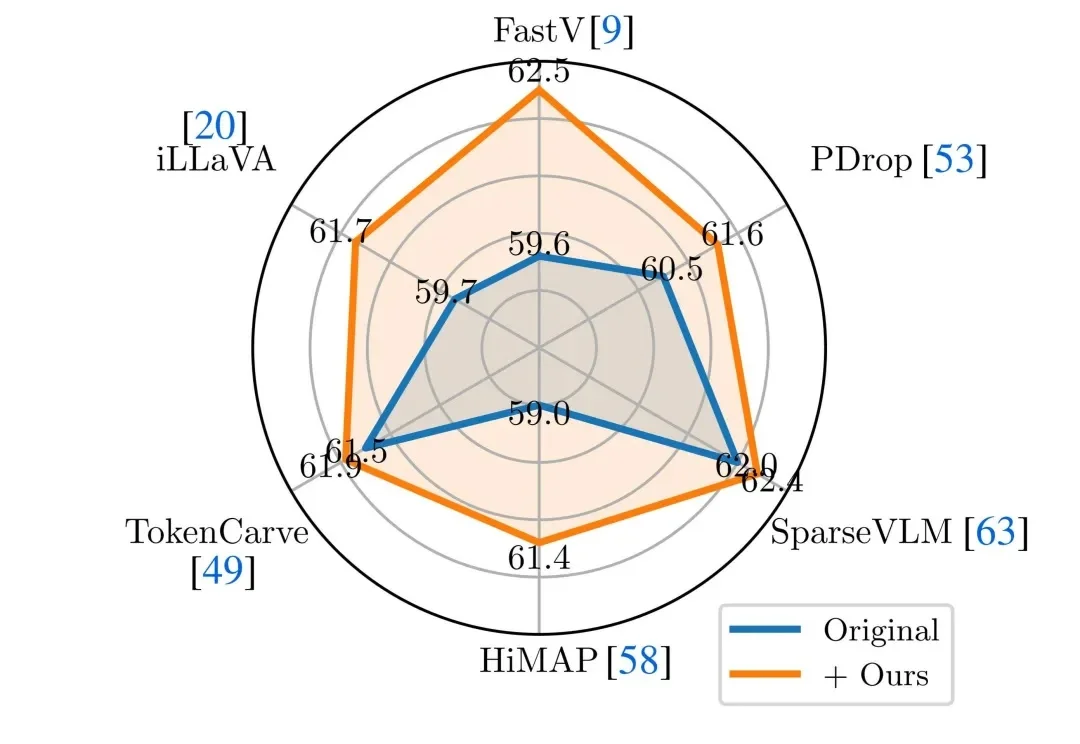
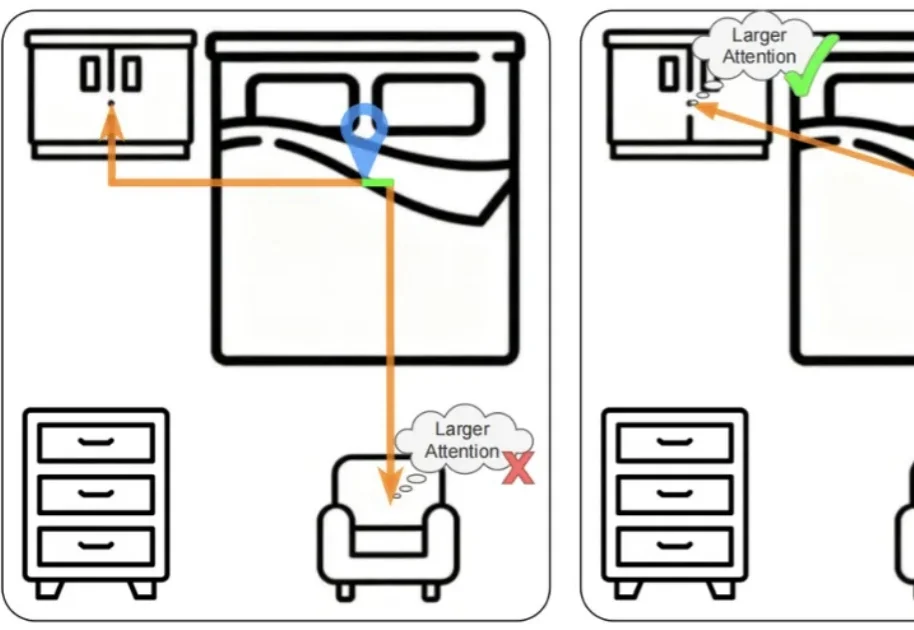
近年来,Vision-Language Models(视觉 — 语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。然而,这类模型在实际应用中往往面临推理开销大、效率受限的问题,研究者通常依赖 visual token pruning 等策略降低计算成本,其中 attention 机制被广泛视为衡量视觉信息重要性的关键依据。
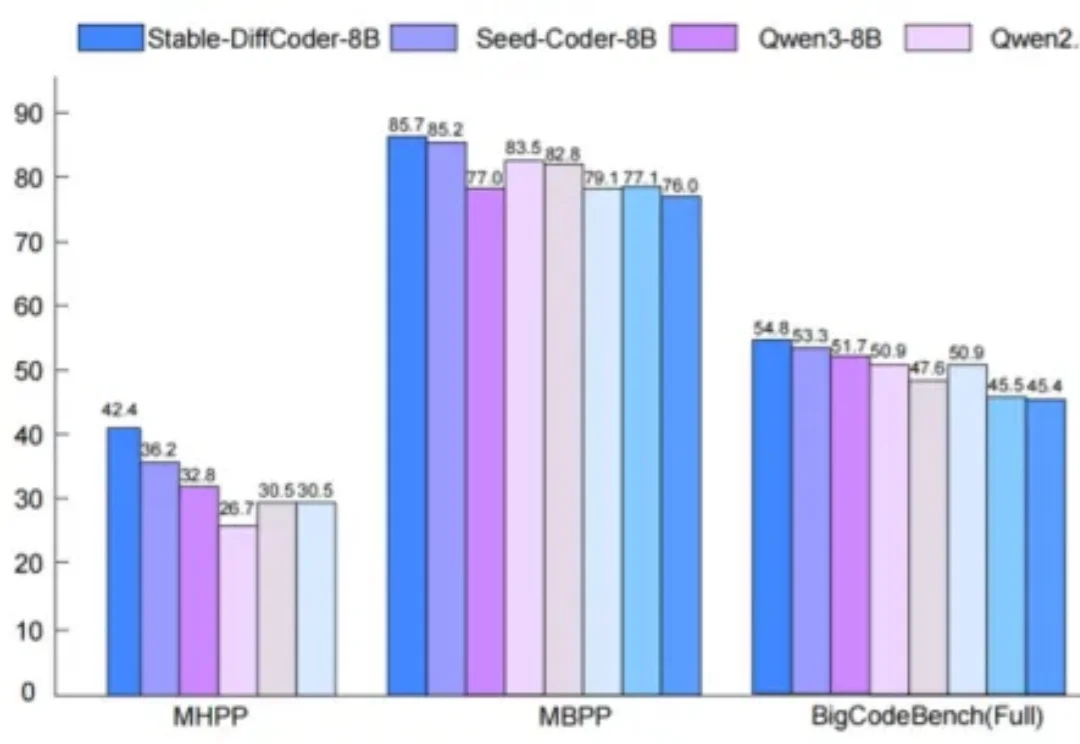
扩散语言模型(Diffusion Language Models, DLLMs)因其多种潜在的特性而备受关注,如能加速的非自回归并行生成特性,能直接起草编辑的特性,能数据增强的特性。然而,其模型能力往往落后于同等规模的强力自回归(AR)模型。
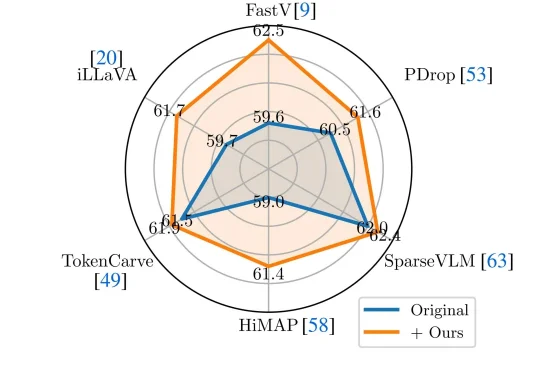
近年来,Vision-Language Models(视觉—语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。